前言
以往想离线运行 LLM 模型,离不开大显存的显卡,还需要手动下载和管理 LLM 模型,推理环境也需要比较繁杂的安装配置,例如安装驱动、安装依赖,有些方案还需要自己执行编译命令。
这一切都非常耗时,哪怕是经验丰富的人也会觉得繁琐。
但是现在 Ollama 的出现让这一切都变得更简单,只需要一条命令即可在本地运行模型:
➜ ollama run openchat
>>> Send a message (/? for help)正因为它的操作如此简便,将复杂的安装和准备环节封装成简单的命令,Ollama 可以称为 LLM 模型版本的 Docker。
介绍
它可以大幅度简化 LLM 的安装、运行、环境配置,你只需要选择一个合适的本地模型,再配合 OpenWebUI 这个前台服务可以达到低配版 ChatGPT Plus 的效果。可以生成图片、可使用 RAG 来索引本地的文件、还可以生成类似 GPTs 的针对特定任务的模型配置。
并且 Ollama 还提供了简洁的跟 OpenAI 一致的 API 调用方式,方便开发者在此基础上做拓展,同时其他的兼容 OpenAI 接口的套壳客户端,也可以直接使用 Ollama 作为 AI 提供方。
当然想在 GPU 上运行模型的要点是需要较大容量的显存。好在我的现在有 MacBook Pro M3 Max 现在 GPU 性能不错,同时拥有 64G 的统一内存让他可以载入一些质量不错的模型,目前只要模型文件大小不超过 30G,都可以顺利运行。
模型的问题是需要较大的参数量才能达到比较好的效果。而参数量大了则会带来更大的模型文件大小,要将其完全载入显存也就占用更多的显存容量。本文说的效果最好实际上是指达到文本生成速度和生成质量的平衡,不至于慢得无法忍受,也不至于答非所问。
安装
macOS 上安装
brew install --cask ollama交互前端
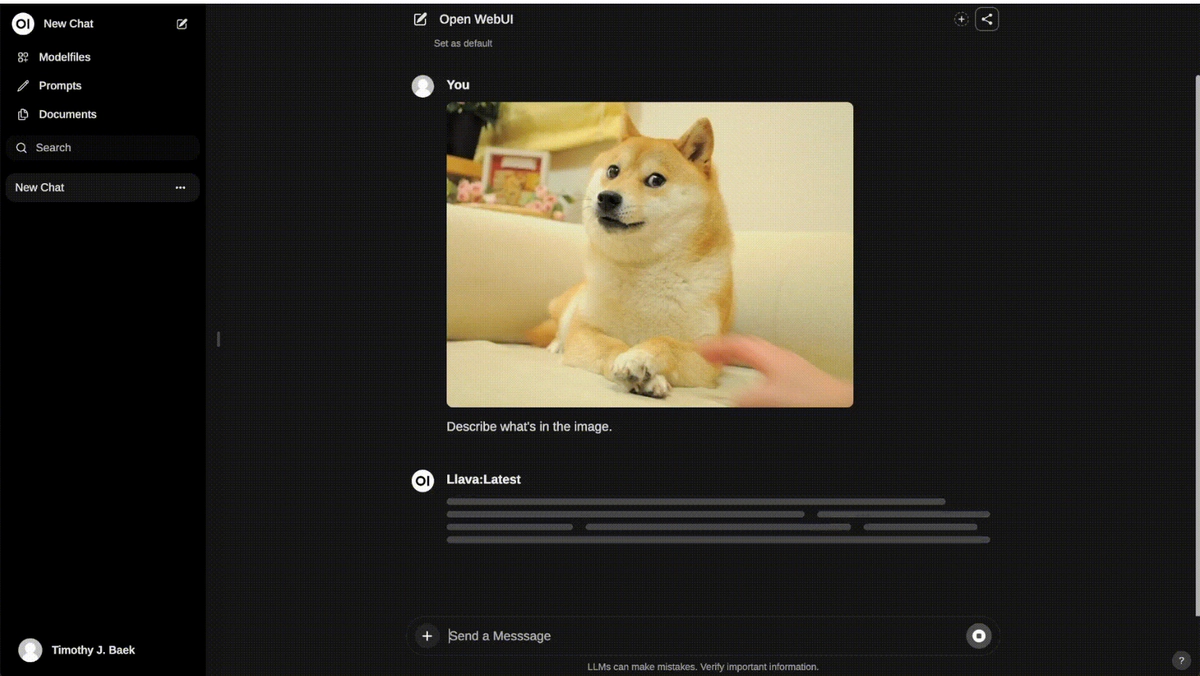
OpenWebUI
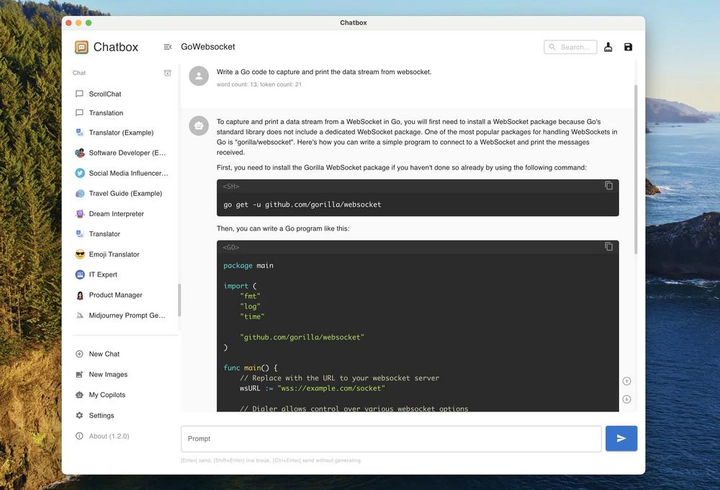
ChatBox
尝试过的模型
# 列出所有的模型
ollama list| NAME | ID | SIZE | MODIFIED |
|---|---|---|---|
| Erosumika-7B.q8_0:latest | 0e7f5eb4fb77 | 7.7 GB | 3 weeks ago |
| causallm:14b-dpo-alpha | ab09d2735a29 | 10 GB | 4 weeks ago |
| causallm:14b-dpo-alpha.Q5_K_M | fd5a7a9a811a | 10 GB | 3 weeks ago |
| code-companion:latest | a531346c68b4 | 26 GB | 4 weeks ago |
| codellama:latest | 8fdf8f752f6e | 3.8 GB | 4 weeks ago |
| deepseek-coder:33b | acec7c0b0fd9 | 18 GB | 4 weeks ago |
| dolphin-mistral:latest | ecbf896611f5 | 4.1 GB | 4 weeks ago |
| dolphin-mixtral:latest | cfada4ba31c7 | 26 GB | 4 weeks ago |
| gemma:7b-instruct-fp16 | f689ad351c8d | 17 GB | 4 weeks ago |
| gemma:latest | 430ed3535049 | 5.2 GB | 4 weeks ago |
| genaiprompt-comma:latest | fe806deca19a | 35 GB | 4 weeks ago |
| linux-terminal:latest | 89cf55e672a4 | 3.8 GB | 4 weeks ago |
| llama2:13b | d475bf4c50bc | 7.4 GB | 4 weeks ago |
| llama2:latest | 78e26419b446 | 3.8 GB | 4 weeks ago |
| llava:latest | 8dd30f6b0cb1 | 4.7 GB | 4 weeks ago |
| mistral:latest | 61e88e884507 | 4.1 GB | 4 weeks ago |
| mixtral:8x7b | 7708c059a8bb | 26 GB | 4 weeks ago |
| mixtral:8x7b-instruct-v0.1-q5_1 | 632b8b96ce22 | 35 GB | 4 weeks ago |
| nomic-embed-text:latest | 0a109f422b47 | 274 MB | 4 weeks ago |
| nous-hermes2-mistral:7b-dpo-q8_0 | 0e1471f9d688 | 7.7 GB | 3 weeks ago |
| nous-hermes2-mixtral:8x7b-dpo-q5_K_M | bce094d11dd6 | 32 GB | 4 weeks ago |
| openchat:7b-v3.5-0106 | 537a4e03b649 | 4.1 GB | 3 weeks ago |
| openchat:latest | 537a4e03b649 | 4.1 GB | 4 weeks ago |
| phi:latest | e2fd6321a5fe | 1.6 GB | 4 weeks ago |
| qwen:14b | 80362ced6553 | 8.2 GB | 3 weeks ago |
| silicon-maid:7b-q5_k_m | 37576a660647 | 5.1 GB | 3 weeks ago |
| stablelm-zephyr:latest | 0a108dbd846e | 1.6 GB | 4 weeks ago |
| starcoder2:3b.q5_1 | 1ba529ebb6f2 | 2.3 GB | 3 weeks ago |
| yi:34b | 5f8365d57cb8 | 19 GB | 3 weeks ago |
| zephyr:7b-beta-q5_K_M | 482c06dc081a | 5.1 GB | 4 weeks ago |
| zephyr:latest | bbe38b81adec | 4.1 GB | 4 weeks ago |
| openllm/causallm:latest | fd5a7a9a811a | 10 GB | 3 weeks ago |
| pxlksr/opencodeinterpreter-ds:latest | 1e582e157f36 | 3.8 GB | 3 weeks ago |
这些模型的总大小已经有 250G 了,占用了相当大的硬盘空间。
➜ cd ~/.ollama
~/.ollama
➜ du -sh
252G .再加上我尝试在本地导入 hugginface 的模型所占用的空间:
➜ du -sh
36G .后面应该尝试精简模型,将其移动到外置硬盘上,只留下效果最好的。
最好的 LLM 模型
模型经过量化后会造成质量损失,我的建议是在机器能够负担的情况下选最大的模型。以下是我推荐的几个模型
通用任务:
- mixtral:8x7b-instruct-v0.1-q5_1
- nous-hermes2-mixtral:8x7b-dpo-q5_K_M
角色扮演:
- silicon-maid:7b-q5_k_m
embedding:
- nomic-embed-text
如何使用 ollama 尚未收录的模型
首先要根据模型的格式来转换
https://github.com/ollama/ollama/blob/main/docs/import.md
其次是要注意 modelfile 的编写
https://github.com/ollama/ollama/blob/main/docs/modelfile.md
注意常见的 ChatML 格式,参考:https://zhuanlan.zhihu.com/p/666461139
一些微小的贡献
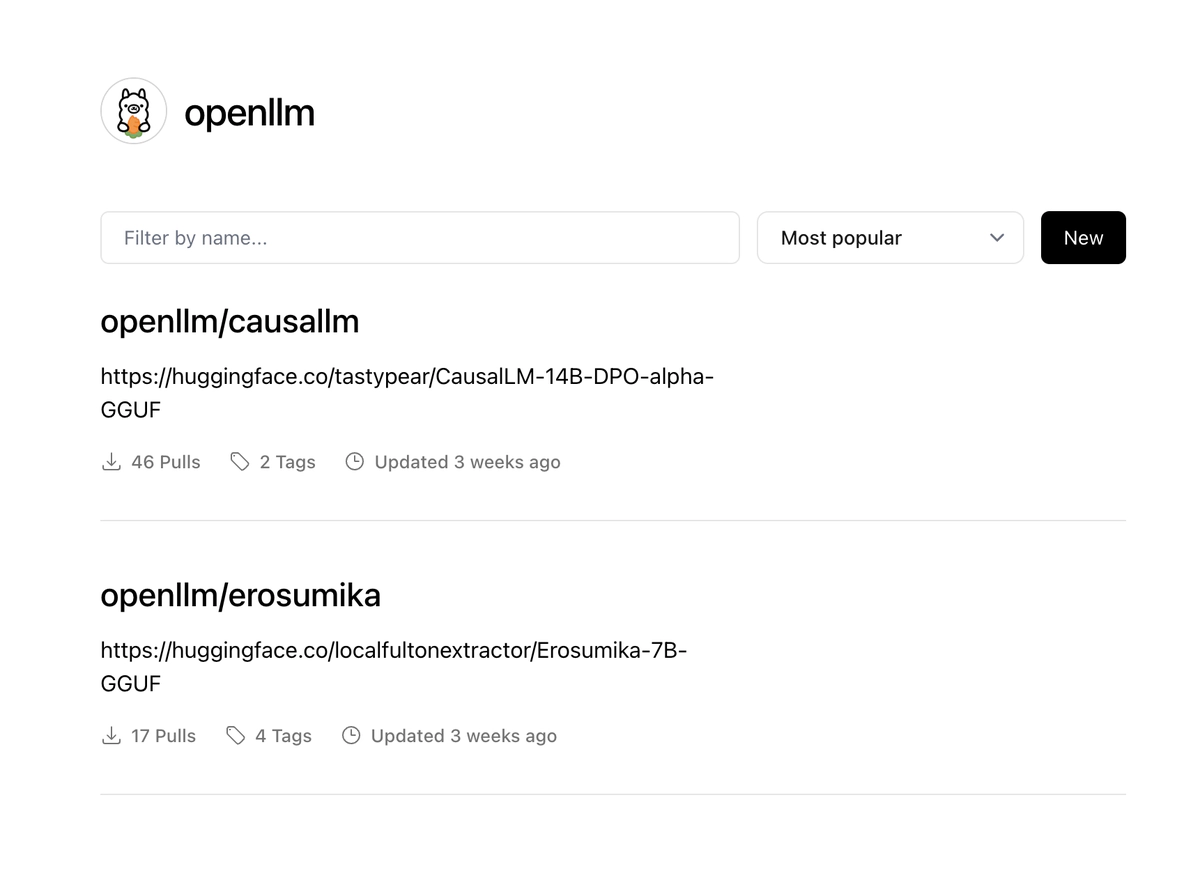
从 hugginface 转载了两个模型到 Ollama 站点。目的是简化 Ollama 来使用 hugginface 模型的流程。
至今为止也为用户提供了一些方便,两个模型加起有 63 次拉取
限制和不足
Ollama 基于 llama.cpp,既可以使用 CPU 来执行推理计算,也可以在符合条件时使用 GPU 来计算,还可以把部分层载入到 GPU 内存,一部分放在系统内存中,代价则是推理速度大大降低。所以想要取得不错的效果,还是得用 GPU。
本地模型的难点是数据和资源较少,开源模型可能很难有资金去持续不断地去优化模型,同时开源模型也更难以收集到真实用户的语料,同时能收集到的数据量也更少。但是另一方面,开源模型或许可以规避一些版权限制,从而利用一些特殊来源的语料来训练模型。
总结
本文中我记录了使用 Ollama 在电脑上体验本地 LLM 的经历,并且提到了配套的 WebUI,以及如何从 Hugginface 上导入并使用 Ollama 上不存在的模型。同时也推荐了一些我认为还不错的模型,避免“不停地下载模型、尝试模型、下载下一个模型”的循环。
本地 LLM 虽好,还是要专注于自己的目标,把精力花在更重要的事情上来。